
Maintenant que l’on a appris à entraîner un réseau de neurones (un modèle) et à récupérer / créer des données d’entraînement, faisons un petit point théorique sur l’optimisation de l’entrainement de notre modèle.
Entraîner un modèle est un processus itératif : à chaque itération, le modèle fait une estimation de la sortie, calcule l’erreur dans son estimation (loss), collecte les dérivées de l’erreur par rapport à ses paramètres et optimise ces paramètres à l’aide de la descente de gradient.
Descente de gradient (rappel)
La descente de gradient est un algorithme permettant de trouver le minimum d’une fonction.
Approche intuitive :
- De façon intuitive, on peut imaginer être un skieur sur une montagne. On cherche à trouver le point d’altitude la plus basse (donc, un minimum d’altitude).
- L’approche pour trouver ce minimum est de se placer face à la pente descendante et de simplement avancer pendant 5 minutes.
- Donc, 5 minutes plus tard, on se trouve à un autre point et on réitère l’étape précédente.
- Ainsi de suite jusqu’à arriver au point le plus bas.

Approche mathématique :
- La pente de la montagne correspond à la dérivée. Et, la valeur de dérivée correspond à l’inclinaison de la pente en un point donné.
- Donc, une dérivée élevée indique une pente importante. De la même façon, si la dérivée est faible, alors la pente est faible. Finalement, une dérivée nulle correspond à un sol horizontal.
- Pour le signe de la dérivée, on va à l’inverse de la pente. Plus concrètement, une dérivée positive indique une pente qui descend vers la gauche et, une dérivée négative indique une pente qui descend vers la droite.
- Une fois la direction déterminée (gauche ou droite), il reste à déterminer le pas (on se déplace pendant 5 minutes, 10 minutes, … ?). L’idéal serait de faire le pas le plus petit possible pour déterminer si on a trouvé le minimum le plus régulièrement possible. Le problème avec cette approche est le coût calculatoire : le calcul va être très lent. A l’inverse, un pas trop grand nous fera louper le minimum. Il faut donc trouver un juste milieu, ce qui se fait en spécifiant un taux d’apprentissage (learning_rate) que l’on développera par la suite.
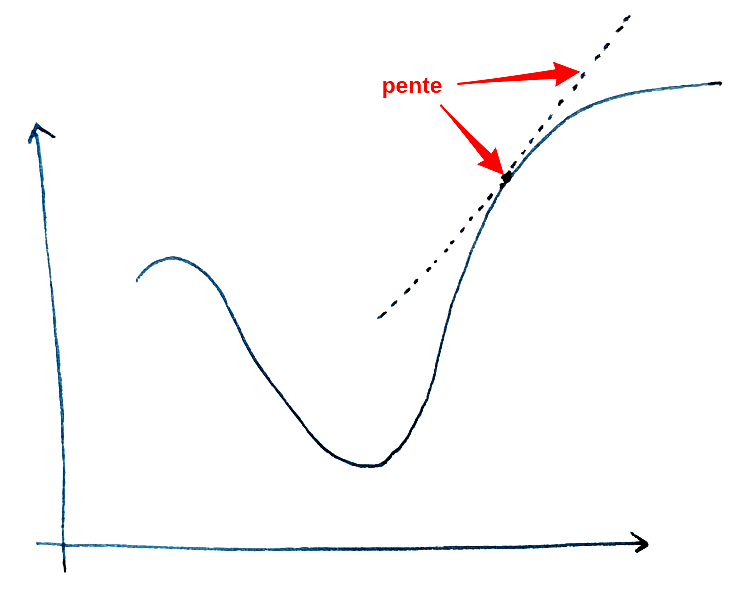
Approches couplées :
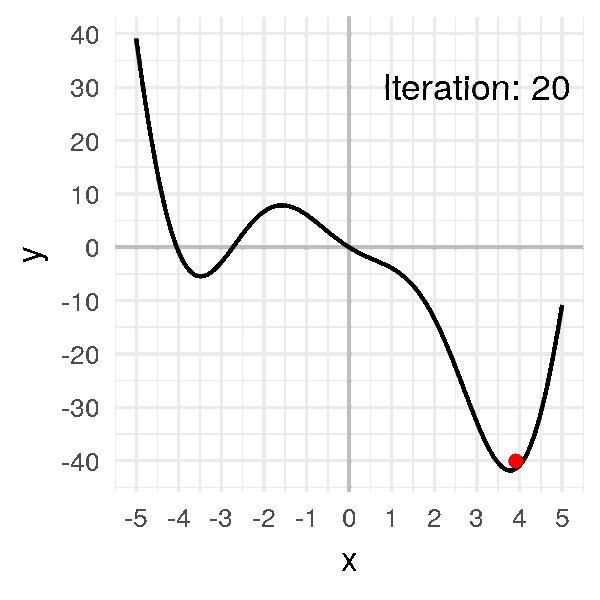
- On peut représenter la montagne décrite dans l’approche intuitive par la fonction suivante : f(x) = 2x²cos(x) – 5x. On se restreindra à une étude sur l’intervalle [-5,5].
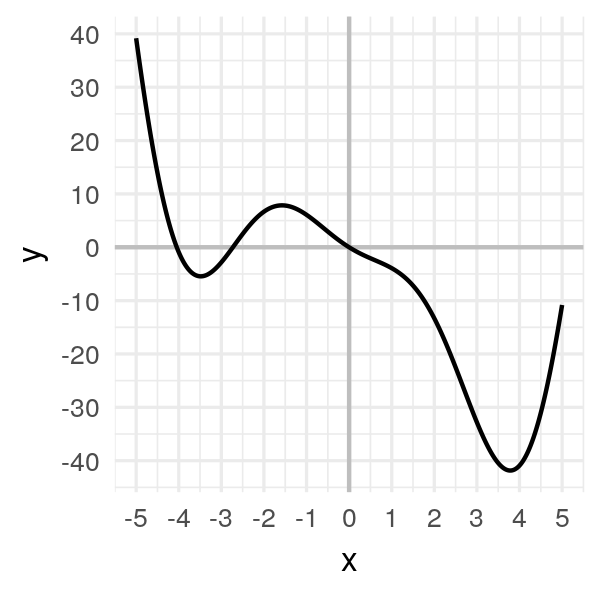
- Visuellement, le minimum est situé vers x ≈ 3.8 pour une valeur minimale de y ≈ -42 environ.
- On va donc appliquer la descente de gradient pour trouver ce minimum.
Pour cela, on commence par prendre un premier x (x0) au hasard. x0 = -1 -> f(x0) = 6.08)
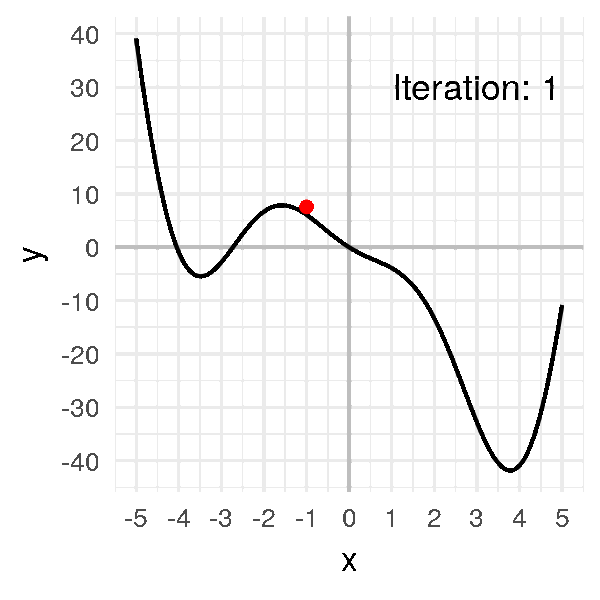
On calcule ensuite la valeur de la pente en ce point (la dérivée f'(x0)). f'(-1) = -2sin(-1)-4cos(-1)-5 ≈ -5.47827
On « avance » dans la direction opposée à la pente : x1 = x0 − αf'(x0) (avec α = learning_rate = 0.05). x1 ≈ -0.72609
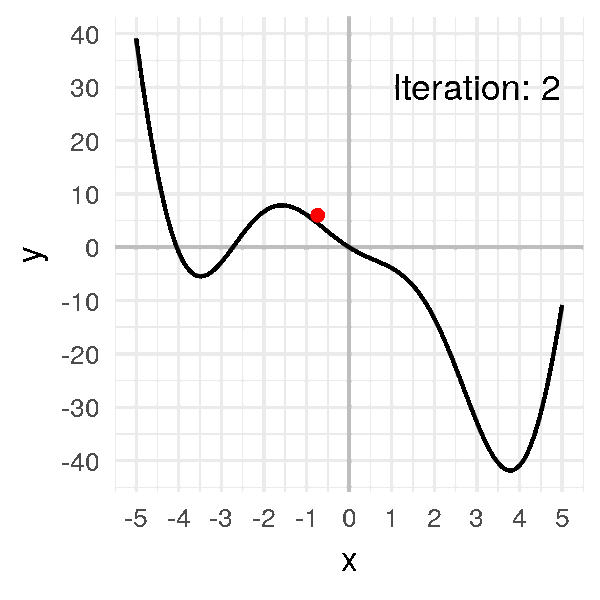
On répète ensuite l’opération jusqu’à trouver xmin. xmin = 3.8
Hyperparamètres
Ce processus d’optimisation peut être influencé directement par le développeur via le biais des hyperparamètres. Ces hyperparamètres sont des paramètres ajustables qui impactent l’entraînement du modèle et le taux de convergence de ce dernier. Le taux de convergence correspond en combien d’itérations le modèle obtient un résultat optimal.
Pour entraîner le modèle, on dispose de 3 hyperparamètres :
- Nombre d’époques epochs_number : le nombre de fois où l’on parcourt l’ensemble de données
- Taille du lot d’entraînement batch_size : le nombre d’échantillons de données propagés sur le réseau avant la mise à jour des paramètres
- Taux d’apprentissage learning_rate : à quel point les paramètres des modèles doivent être mis à jour à chaque lot/époque. Des valeurs plus petites entraînent une vitesse d’apprentissage lente, tandis que des valeurs plus élevées peuvent entraîner un comportement imprévisible pendant l’apprentissage. (ref. « Descente de gradient »)
Explication des hyperparamètres
Plus concrètement, on possède initialement 2 choses :
- le modèle
- un jeu de données
On commence par découper le jeu de données en sous-jeux de données, tous de même taille. Ces sous-jeux de données sont appelés batch, tous de taille batch_size.
Ensuite, chaque batch est propagé dans le réseau (passé en entrée de celui-ci). Lorsque tous les batch sont passés par le modèle, on a réalisé 1 epoch. Le processus est alors reproduit epochs_number nombre de fois.
Ces étapes peuvent être visualisées sur l’image suivante.
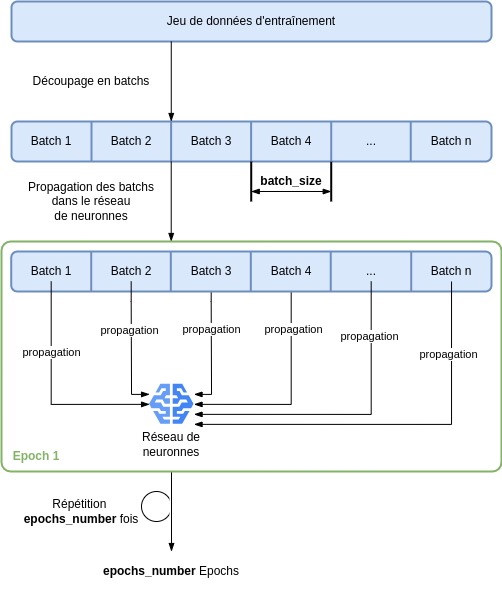
Boucle d’entraînement du modèle
Avant toute chose il faut définir les hyperparamètres. Par exemple :
- learning_rate = 1e-3
- batch_size = 64
- epochs = 5
Une fois les hyperparamètres définis la boucle d’entraînement et d’optimisation du modèle peuvent commencer. Pour rappel, chaque itération de cette boucle est donc une epoch.
De façon plus précise chaque epoch est constituée de 2 phases :
- l’entraînement : itération sur le jeu de données d’entraînement afin de tenter de converger vers des paramètres optimaux.
- la validation : itération sur le jeu de données de validation pour vérifier que le modèle est plus performant et s’améliore.
A la première boucle, comme notre réseau n’a pas encore été entraîné, il a très peu de chance qu’il donne une bonne réponse / un bon résultat. Il faut alors mesurer la distance entre le résultat obtenu et le résultat attendu. Cette distance est calculée à l’aide de la fonction de perte (loss_function).
Le but est donc, au fur et à mesure des itérations de boucle, de minimiser cette loss_function afin d’avoir un résultat obtenu au plus proche du résultat attendu. On notera ici l’utilité de la descente de gradient qui, comme expliqué précédemment, est un algorithme permettant de trouver le minimum d’une fonction, ici, la loss_function.
L’optimisation consiste donc à mettre à jour les paramètres à chaque boucle pour minimiser cette fonction de perte. Cette optimisation est encapsulée dans un objet optimizer qui est appliqué sur le modèle. Ce dernier prend donc en entrée les hyperparamètres du modèle. Dans la boucle d’entrainement, l’optimisation est plus précisément réalisée en 3 étapes :
- Appel à fonction optimizer.zero_grad() : réinitialisation des gradients des paramètres du modèle. Par défaut, les gradients s’additionnent ; pour éviter le double comptage, nous les mettons explicitement à zéro à chaque itération.
- Appel à la fonction loss.backward() : rétropropagation de la prédiction de perte (loss).
- Appel à la fonction optimizer.step() : ajustement des paramètres par les gradients collectés lors de la rétropropagation.
Conclusion
Nous avons révisé comment entraîner un modèle de données en introduisant les concepts de hyperparamètres et touché du doigt l’importance d’un bon optimiseur.
La prochaine fois nous vous proposerons un TP pour coder notre optimiseur et étudier quelques uns des optimiseurs fournis dans pytorch.
Rédacteurs : Mathilde Pommier et Sébastien Da Rocha