
Mais, bien plus encore, ces réseaux de neurones sont également utilisés pour classifier des données ou bien effectuer des prévisions. Ils sont également très utilisés dans le domaine du traitement du langage ou bien celui de la vision par ordinateur, notamment en robotique. Les réseaux de neurones sont donc présents partout autour de nous.
Cependant, vous ne savez peut-être pas ce qui se cache derrière ces réseaux qui peuvent paraître très obscurs et complexes. Si vous souhaitez comprendre et utiliser ces systèmes de détection, classification et prédiction, il vous faudra d’abord appréhender la notion de réseaux de neurones. Pour cela, nous allons développer un exemple concret.
Exemple concret – Classification d’une image
Un réseau de neurones peut par exemple être utilisé pour classer une image dans telle ou telle catégorie. Un exemple concret pourrait être l’application de cette technologie à la détection et la classification des sols sur des images satellites.
L’idée est donc de donner une image en entrée du réseau de neurones et que celui-ci classe cette image dans la catégorie “urbain” ou bien « rural” par exemple. Le problème revient donc à se poser la question suivante : « Mon image représente-t-elle une zone urbaine ? »
Si l’on crée le réseau et qu’on donne tout de suite notre image en entrée, on aura un résultat aléatoire, aberrant et très peu exact. Il faut donc entraîner notre réseau avec un jeu de données pour lui apprendre à bien classifier les images. On lui donne donc beaucoup d’images de zones urbaines et rurales pour lui apprendre à les différencier correctement.
Il existe différentes méthodes d’apprentissage mais la plus répandue (et simple à la compréhension) est l’apprentissage supervisé. Cela consiste à donner le résultat attendu en même temps que la donnée d’entrée. Plus concrètement, chaque image est annotée avec la catégorie “urbain” ou “rural” afin que le réseau puisse confirmer ses résultats et ainsi apprendre de ses erreurs. C’est cette méthode d’apprentissage qui sera expliquée par la suite.
Un réseau de neurones est basé sur le fonctionnement du cerveau humain. Il est donc composé de plusieurs neurones reliés entre eux de la façon suivante :
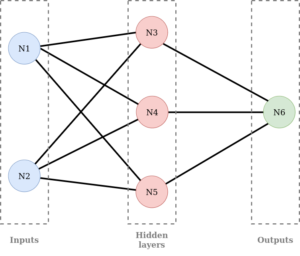
Comme on peut le voir, les neurones sont divisés en 3 familles :
– les entrées : inputs
– les neurones des couches cachées : hidden layers
– les sorties : outputs
Dans notre réseau nous avons : 2 inputs, 1 hidden layer avec 3 neurones et 1 output.
Il est cependant possible d’avoir autant de neurones que l’on veut dans chaque famille ; on peut également avoir plusieurs couches cachées.
Une fois le réseau créé, on peut maintenant s’intéresser à son fonctionnement qui consiste en deux phases : la phase de feed forward et celle de back propagation.
La phase de feed forward consiste à introduire les données en entrée du réseau et de les propager à travers celui-ci. Pour résumer, à chaque couche on calcule la somme pondérée des entrées puis cette valeur est transmise via une fonction d’activation. On reproduit ensuite le processus jusqu’à la couche de sortie. Cette phase est donc celle de prédiction et est utilisée pour l’inférence.
La phase de back propagation arrive une fois la prédiction effectuée. On calcule alors l’erreur entre la sortie prédite et la sortie réelle. Puis cette dernière est propagée dans le réseau et les poids sont ajustés au fur et à mesure pour minimiser cette erreur.
L’apprentissage consiste donc en une multitude de cycles : feed forward + back propagation.
Nous allons maintenant observer la phase de feed forward plus en détails. Cette étape commence par donner une première fois des données en entrée de notre réseau. Chaque neurone de la couche inputs se voit donc affecté d’une valeur. Dans notre cas “Mon image représente-t-elle une zone urbaine ?” on aura des valeurs numériques entre 0 et 1 (probabilité que l’image présente une zone rurale) :
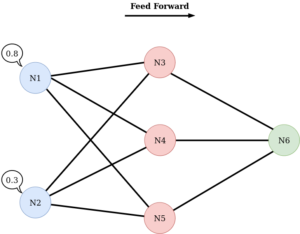
Les valeurs sont ensuite transmises aux neurones de la couche suivante par les connexions :
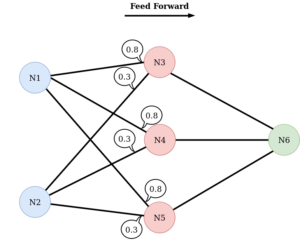
Les neurones de la deuxième couche fusionnent donc les valeurs des neurones de la couche précédente. La valeur fusionnée obtenue peut ensuite être modifiée en interne par le neurone :
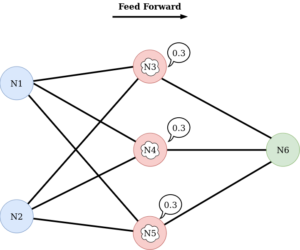
Puis les neurones de la deuxième couche transmettent à leur tour la valeur modifiée à la couche suivante :
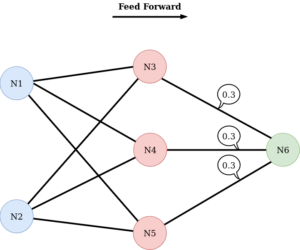
De la même façon, le(s) neurone(s) de la couche finale (outputs), peu(ven)t modifier en interne la valeur reçue avant de la retourner :
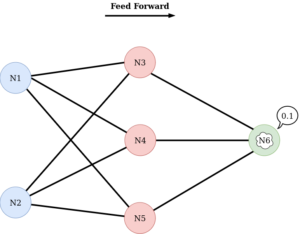
Une fois la valeur finale obtenue, on a fini la passe de feed forward.
En réalité, la transmission des valeurs est un peu plus complexe. C’est ce qu’on va détailler par la suite. Pour bien comprendre la transmission, on va se limiter à 3 neurones.
La transmission des valeurs va dépendre de « l’épaisseur » du lien entre les neurones. Plus le lien est épais, plus la valeur passe dans son intégralité et inversement. Cette épaisseur est appelée poids ou weight et est différente pour chaque lien, comme visible sur l’image suivante :
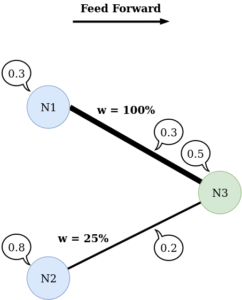
Ainsi, chaque neurone n’a pas le même poids / la même importance dans le réseau.
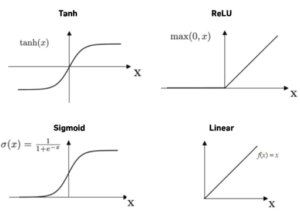
On va maintenant voir comment le neurone peut changer en interne la valeur qu’il reçoit avant de la transmettre. Concrètement, le neurone possède une fonction, dite fonction d’activation, qui sert à déterminer si la valeur doit ou non passer au prochain neurone. Si le résultat de la fonction est proche de 1, la valeur passera et s’il est proche de 0, la valeur ne passera pas.
Il existe une multitude de fonctions d’activation mais les plus utilisées sont :
– Sigmoid
– Unité linéaire rectifiée (Rectified Linear Unit : ReLU)
– Tangente Hyperbolique (tanh)
– Linear
Le neurone a également la possibilité d’ajouter un biais en entrée de la fonction d’activation, ce qui permet au neurone d’avoir de l’influence sur l’activation :
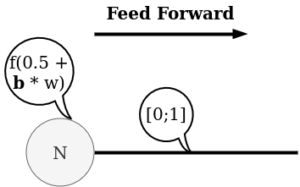
Pour résumer :
– on a un ensemble de neurones
– on entre les données dans les neurones inputs
– on lie les couches de neurones avec un certain poids
– on ajoute des biais, qui sont multipliés par leur propre poids
– on ajoute les valeurs pour avoir les nouvelles valeurs
– on fait passer les nouvelles valeurs dans la fonction d’activation
– on récapitule pour le dernier neurone
On obtient finalement le résultat.
Cependant, comme on initialise les biais et les poids aléatoirement, il y a peu de chance pour que le réseau soit performant.
On va alors passer notre résultat dans une fonction d’erreur. Cette fonction prend en entrée notre résultat et la valeur attendue. Cela nous permet de déterminer la précision de notre réseau.
On va ensuite réaliser la deuxième étape : la passe de back propagation. De manière très simple, cette étape consiste à déterminer comment on doit modifier les poids de notre réseau pour faire diminuer au maximum notre erreur. Dans la pratique, on modifie un poids à la fois et très peu pour déterminer l’influence de chaque poids sur notre réseau en fonction de son impact sur l’erreur. Cette étape est réalisée par les dérivées de tous les calculs fait lors de la phase de feed forward.
Conclusion
Nous avons découvert ce qui se cache derrière un réseau de neurones, son fonctionnement basique ainsi que ses applications diverses. Les réseaux de neurones offrent de nombreuses possibilités pour le domaine de la géomatique avec l’analyse et l’interprétation des données spatiales. La capacité de ces derniers à apprendre à partir de données brutes en fait un outil puissant pour la prédiction, la classification, et même la génération de nouvelles données géospatiales. Cependant, il est essentiel de se rappeler que, malgré leur potentiel, les réseaux de neurones ne sont pas une solution miracle et peuvent présenter des défis en pratique. Il est notamment important de rappeler que la qualité et la quantité des données sont primordiales afin d’obtenir des résultats fiables et significatifs. Finalement, il est également essentiel de noter que l’utilisation efficace des réseaux de neurones nécessite souvent des capacités de calcul élevées et des ensembles de données volumineux.
Rédactrice : Mathilde POMMIER