
ChatGPT est un agent conversationnel qui peut vous aider au quotidien. Néanmoins, vous ne savez pas réellement ce que OpenAI, son créateur, fait de vos conversations. Il n’est, d’ailleurs, pas conseillé de lui parler de sujets confidentiels.
Si vous souhaitez l’utiliser dans vos produits, l’API peut rapidement coûter très cher (compter environ 3 centimes pour le traitement de cet article par exemple, multiplié par le nombre de requêtes par utilisateur, multiplié par les demandes de chaque utilisateur…). Heureusement, la communauté Open Source propose petit à petit des alternatives.
La première étape était la publication de Llama par Meta (Facebook). Il s’agit d’un modèle d’intelligence presque libre et limité à 500 millions d’utilisateurs. Au-delà, il faut les contacter pour avoir le droit de l’utiliser. Il est également possible de le récupérer sur nos ordinateurs et de s’en servir de façon strictement privée.
Pour télécharger le modèle, il faut néanmoins montrer patte blanche en remplissant un formulaire et recevoir un lien, par mail, avec une durée de vie limité. En cas d’expérimentation, cela peut vite devenir contraignant.
Démocratisation technique
Les développeurs de llama.cpp (surtout Georgi GERGANOV) ont optimisé ce moteur qui vous permet de discuter avec les modèles Llama2.
Les modèles de Llama2
Llama2 est disponible en plusieurs tailles (nombre de paramètres) : 7B, 13B et 70B. L’unité « B » correspond à des milliards de paramètres.
Sachant que chaque paramètre est stocké sur 2 octets (des flottants de demi-précision), il faut au moins 16Go de RAM pour charger le petit modèle 7B. Les gros modèles sont plus pertinents, mais beaucoup plus lents.
Les optimisations
Les développeurs de LLama.cpp ont travaillé sur 2 optimisations :
- Pouvoir lancer les calculs (appelés « inférence ») sur le CPU en utilisant au maximum ses capacités (optimisation M1, AVX-512 ou AVX2…) et en codant le moteur d’inférence en C++ et sûrement des morceaux en assembleur ;
- Compresser le modèle sans trop perdre de pertinence.
Pour ce dernier point, ils ont développé un codage flottant du 4bits : q4_0 (d’autres variantes avec plus de bits existent). Nous pouvons désormais utiliser un modèle 7B avec 4Go de RAM ! À noter que l’on peut tout de même un peu perdre en pertinence.
Le travail de llama.cpp est prodigieux mais difficile à utiliser : il arrive que le modèle réponde de manière erronée ou ne rende pas la main après la réponse.
Ollama
Désormais la relève existe : Ollama !
Considéré comme le docker des LLM, il nous permet de télécharger, questionner, supprimer des modèles en une ligne de commande. Concernant les performances, Ollama est une surcouche en Go et utilise llama.cpp.
Les instructions d’installation sont disponibles ici : https://ollama.ai/download.
Une fois installé, vous pouvez télécharger un modèle aussi simplement que :
ollama pull llama2Une fois téléchargé, vous pouvez le questionner comme ceci :
ollama run llama2
>>> comment faire une jointure entre 2 dataframes Pandas ?
There are several ways to join two pandas DataFrames. Here are a few methods:
1. `merge()`: This is the most common method for joining two DataFrames. It joins the two DataFrames based on a common column, called the "join key". The joined DataFrame will have the columns from both DataFrames.
```
df_left = pd.read_csv('left_data.csv')
...Attention, Ollama installe aussi un service Systemd en arrière-plan. Si vous préférez le lancer manuellement, au hasard pour contrôler la RAM de disponible sur votre machine, vous devez :
# désactiver le démarrage auto avec la machine
sudo systemctl disable ollama.service
# Couper réellement le service
sudo systemctl stop ollama.serviceQuel modèle ?
Llama a apporté son lot de révolutions, mais d’autres équipes de chercheurs ont repris le flambeau, notamment Mistral AI qui a réussi à créer des petits modèles très efficaces.
Récemment, Hugging Face (l’équivalent de Github dans la sphère IA) a encore amélioré Mistral en créant Zephyr, un petit modèle qui a de très bon résultats pour parler dans plusieurs langues.
ollama run zephyr:7b
>>> comment faire une jointure entre 2 dataframes Pandas ?
Pour joindre deux DataFrames en Pandas, vous pouvez utiliser la méthode `merge()`. Ci-dessous une explication de comment utiliser cette méthode :
1. Assurez-vous que les deux DataFrames ont une colonne commune sur laquelle joindre les données. Soit df1 et df2, on appellera cette colonne 'common_column'.
...Zephyr n’a pas de clause de restriction à 500 millions d’utilisateurs (licence Apache 2.0), il répond en français et sera plus économe en ressources.
Ci-dessous, une liste de quelques modèles :
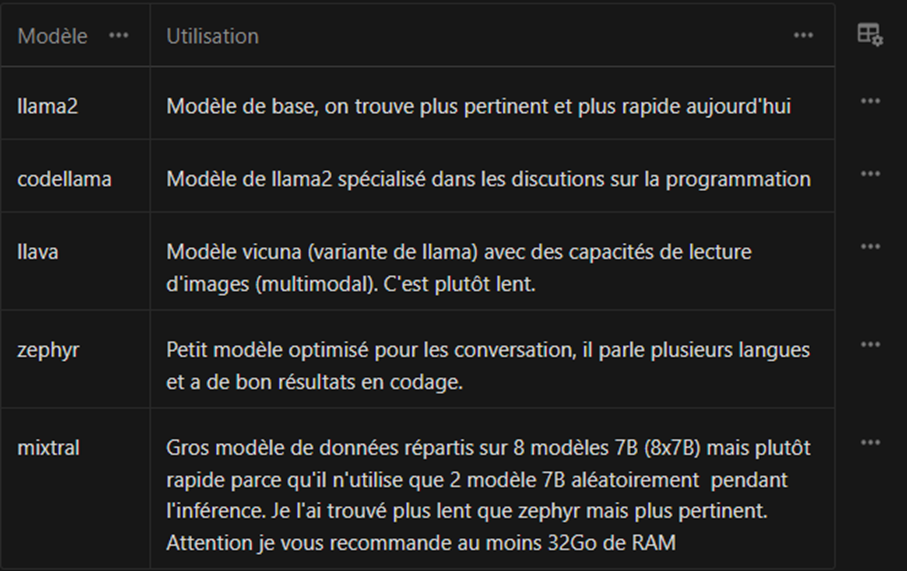
S’il en détecte un, Ollama va automatiquement utiliser le GPU. Sinon, il se rabat sur le CPU en essayant de tirer parti des instructions disponibles (AVX2, AVX512, NEON pour les M1/M2…)
Docker
Si vous utilisez l’image docker de Ollama, il faut penser à couper le service Ollama ou à changer de port TCP d’écoute dans le docker-compose.yaml.
Voici un docker-compose minimaliste :
---
version: '3.8'
services:
ollama:
image: ollama/ollama:latest
ports:
- "11434:11434"
volumes:
- ollama:/root/.ollama
restart: unless-stopped
volumes:
ollama:Ensuite, un petit docker compose up -d pour lancer le serveur.
Comment pouvons-nous alors lancer une inférence ?
$ docker compose exec ollama ollama run zephyr:7b
>>> Salut
Bonjour,
Je suis heureux d'aider quelqu'un aujourd'hui. Votre expression "Salut" est une forme courante de salutation en français. En France, c'est souvent utilisé entre amis ou entre personnes qui connaissent déjà l'un l'autre. Dans les situations où vous souhaitez être plus formel ou professionnel, vous pouvez utiliser "Bonjour" ou "Bonsoir" suivi du prénom de la personne ou simplement "Madame" ou "Monsieur" si vous ne connaissez pas le prénom.
J'espère que cela vous a été utile. Si vous avez d'autres questions, n'hésitez pas à me contacter.
Bien à vous,
[Votre nom]
>>> En revanche, utiliser la console de l’image n’est pas pratique, sauf si vous souhaitez télécharger une image et plus jamais y retoucher. Et surtout, nous pouvons utiliser l’API HTTP :
curl -X POST http://localhost:11435/api/generate -d '{ "model": "zephyr:7b", "prompt": "raconte moi une courte histoire drôle"}'
{"model":"zephyr:7b","created_at":"2024-01-11T15:27:47.516708062Z","response":"Il","done":false}
{"model":"zephyr:7b","created_at":"2024-01-11T15:27:47.534749456Z","response":" y","done":false}
...Pour faciliter la lecture de l’inférence, vous pouvez afficher le texte token par token dans notre app. Il est également possible de s’en servir en python. Voici un exemple de client inclut dans le dépôt :
https://github.com/jmorganca/ollama/blob/main/api/client.py
Il est toujours possible d’utiliser le client installé précédemment ollama en ligne de commande, pour requêter le serveur à distance :
OLLAMA_HOST=127.0.0.1:11435 ollama run zephyr:7b-beta-q6_K "raconte moi une courte histoire drôle"Docker et l’accélération avec une carte graphique Nvidia
Vous remarquerez que l’inférence dans le docker n’est pas très rapide. En effet, docker ne laisse pas le container accéder à la carte graphique, par conséquent l’inférence se fait sur le CPU.
Pour cela, il faut installer un paquet fourni par Nvidia afin de configurer le docker proprement :
curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg \
&& curl -s -L https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list | \
sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | \
sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list
apt update
apt install -y nvidia-container-toolkitUne fois ce paquet installé, il faut utiliser l’outil fournit pour configurer docker :
sudo nvidia-ctk runtime configure --runtime=dockerCela va modifier votre configuration de docker /etc/docker/daemon.json pour activer un runtime nvidia :
{
"runtimes": {
"nvidia": {
"args": [],
"path": "nvidia-container-runtime"
}
}
}Ensuite, il suffit de redémarrer docker :
systemctl restart dockerDésormais, vous devriez pouvoir accéder à votre GPU Nvidia depuis le container :
$ docker run --rm --runtime=nvidia --gpus all ubuntu nvidia-smi
Unable to find image 'ubuntu:latest' locally
latest: Pulling from library/ubuntu
a48641193673: Already exists
Digest: sha256:6042500cf4b44023ea1894effe7890666b0c5c7871ed83a97c36c76ae560bb9b
Status: Downloaded newer image for ubuntu:latest
Thu Jan 11 15:46:38 2024
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 525.147.05 Driver Version: 525.147.05 CUDA Version: 12.0 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 NVIDIA GeForce ... On | 00000000:2D:00.0 On | N/A |
| 31% 33C P5 32W / 225W | 1778MiB / 8192MiB | 2% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
+-----------------------------------------------------------------------------+Une fois cela terminé, l’accès doit être donnée à votre container en modifiant le docker-compose.yaml:
---
version: '3.8'
services:
ollama:
image: ollama/ollama:latest
ports:
- "11435:11434"
volumes:
- ollama:/root/.ollama
restart: unless-stopped
deploy:
resources:
reservations:
devices:
- driver: nvidia
capabilities: [gpu]
count: all
volumes:
ollama:Grâce au docker compose up -d, notre inférence est désormais beaucoup plus rapide.
Conclusion
Nous avons découvert comment utiliser les LLM libre, avec des projets comme Ollama et Zephyr, qui rendent l’IA plus démocratique et accessible à un plus grand nombre. Plus besoin de se soucier des coûts prohibitifs de l’API OpenAI, lorsque vous pouvez exploiter ces modèles de langage gratuits et Open source.
Que vous soyez un développeur, un chercheur ou un professionnel de l’IA, Ollama offre des opportunités passionnantes pour innover, créer et résoudre des problèmes. Le monde de l’IA est désormais entre vos mains.
Sources :
https://www.unite.ai/fr/zephyr-7b-huggingfaces-llm-hyper-optimisé-construit-au-dessus-du-mistral-7b/
https://ollama.ai/blog/ollama-is-now-available-as-an-official-docker-image
https://github.com/jmorganca/ollama/blob/main/README.md#quickstart
https://docs.nvidia.com/datacenter/cloud-native/container-toolkit/latest/install-guide.html
https://docs.nvidia.com/datacenter/cloud-native/container-toolkit/latest/sample-workload.html
Rédacteur : Sébastien DA ROCHA