Pour mieux comprendre l’article sur les réseaux de neurones, cette semaine nous vous proposons de coder un petit réseau de neurones de façon à mieux comprendre ce que sont les poids, le feed forward et les autres notions introduites dans l’article précédent.
Nous allons réaliser un réseau de neurones à 1 neurone et essayer de lui faire prédire des données placées sur une droite. Cet exercice est trivial, on peut le résoudre sans utiliser d’IA mais restons un peu humble pour commencer.
Préparation du projet
Utilisons Jupyter qui reste l’outil de prédilection pour tester et développer une IA.
# On crée un environnement virtuelle python, et on l'active
python3 -m venv test_ia
cd test_ia
. bin/activate
# On installe jupyter et on le lance
pip install jupyter
jupyter notebookCette dernière commande ouvrira Jupyter dans votre navigateur.
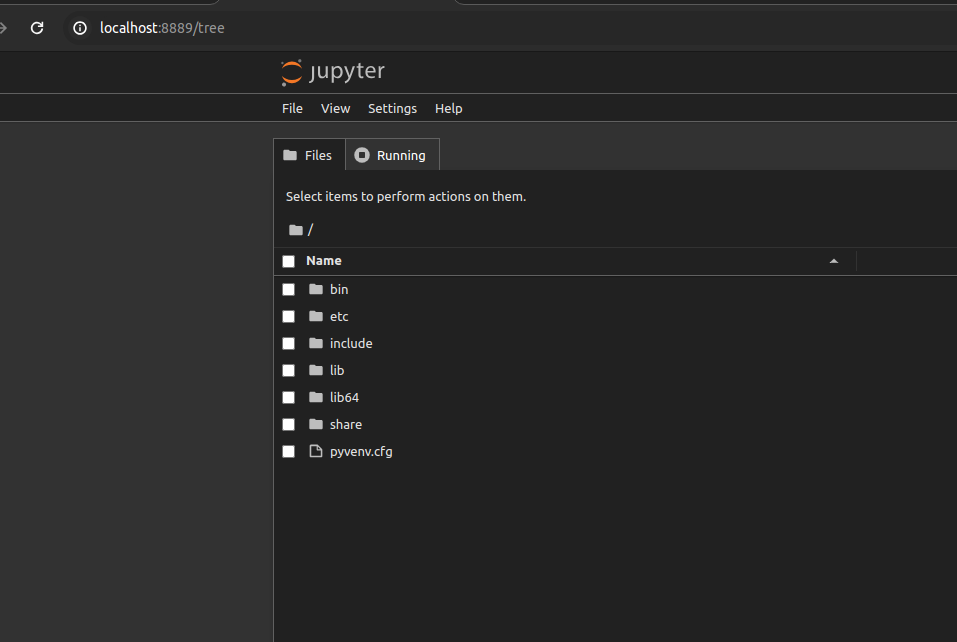
Vous pourrez aller dans “File” -> “New” -> “Notebook” pour créer un nouveau fichier et copier/tester notre programme.
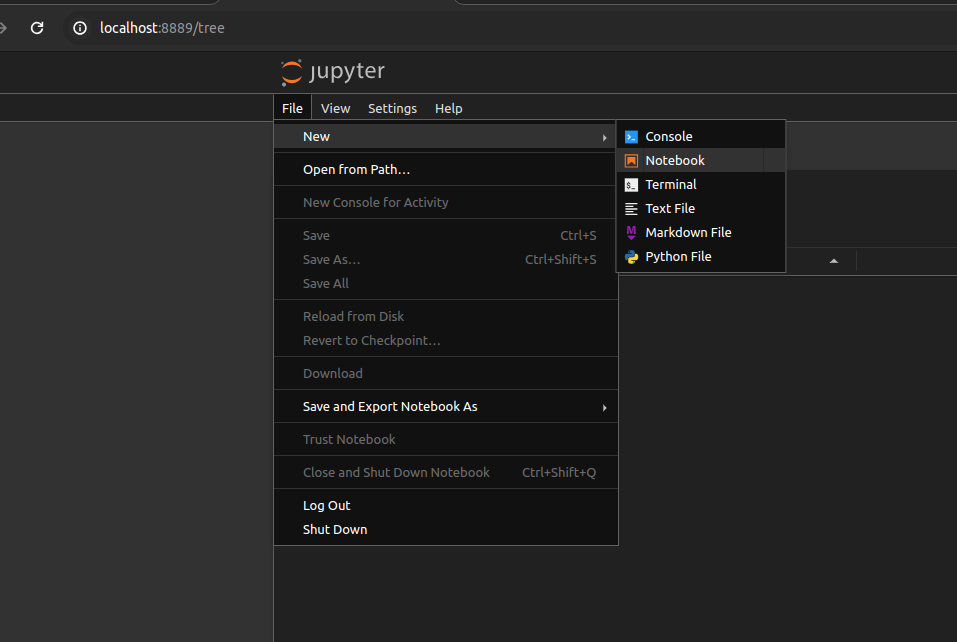
Si l’option « Notebook » n’est pas disponible, remplacez « tree » par « lab » dans votre URL. L’interface sera alors légèrement différente mais vous pourrez créer un nouveau Notebook depuis « File » -> « New » -> « Notebook ».
De quoi avons-nous besoin ?
Numpy, c’est une bibliothèque Python optimisée pour la gestion de listes.
NB : il y a un point d’exclamation en début de ligne, ce qui signifie que la commande sera lancée dans le shell. Ici elle permettra d’installer les dépendances dans notre environnement virtuel.
!pip install numpy
import numpy as np
Requirement already satisfied: numpy in /home/seba/.local/share/virtualenvs/blog-simple-neural-network-F0Tscko_/lib/python3.11/site-packages (1.26.4)Pandas, la bibliothèque Python star de la data-science, basée elle-même sur Numpy.
!pip install pandas
import pandas as pd
Requirement already satisfied: pandas in /home/seba/.local/share/virtualenvs/blog-simple-neural-network-F0Tscko_/lib/python3.11/site-packages (2.2.2)
Requirement already satisfied: numpy>=1.23.2 in /home/seba/.local/share/virtualenvs/blog-simple-neural-network-F0Tscko_/lib/python3.11/site-packages (from pandas) (1.26.4)
Requirement already satisfied: python-dateutil>=2.8.2 in /home/seba/.local/share/virtualenvs/blog-simple-neural-network-F0Tscko_/lib/python3.11/site-packages (from pandas) (2.9.0.post0)
Requirement already satisfied: pytz>=2020.1 in /home/seba/.local/share/virtualenvs/blog-simple-neural-network-F0Tscko_/lib/python3.11/site-packages (from pandas) (2024.1)
Requirement already satisfied: tzdata>=2022.7 in /home/seba/.local/share/virtualenvs/blog-simple-neural-network-F0Tscko_/lib/python3.11/site-packages (from pandas) (2024.1)
Requirement already satisfied: six>=1.5 in /home/seba/.local/share/virtualenvs/blog-simple-neural-network-F0Tscko_/lib/python3.11/site-packages (from python-dateutil>=2.8.2->pandas) (1.16.0)
Pytorch, une des principales bibliothèques Python pour faire des réseaux de neurones. Ici on n’installe que la version CPU, la version de base fonctionne avec CUDA, la bibliothèque de calcul scientifique de Nvidia, mais celle-ci prend beaucoup de place sur le disque dur, restons frugaux.
!pip3 install torch --index-url https://download.pytorch.org/whl/cpu
import torch
import torch.nn.functional as F
Looking in indexes: https://download.pytorch.org/whl/cpu
Collecting torch
Downloading https://download.pytorch.org/whl/cpu/torch-2.3.1%2Bcpu-cp311-cp311-linux_x86_64.whl (190.4 MB)
[2K [38;2;114;156;31m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━[0m [32m190.4/190.4 MB[0m [31m26.4 MB/s[0m eta [36m0:00:00[0mm eta [36m0:00:01[0m[36m0:00:01[0m
[?25hCollecting filelock
Downloading https://download.pytorch.org/whl/filelock-3.13.1-py3-none-any.whl (11 kB)
Requirement already satisfied: typing-extensions>=4.8.0 in /home/seba/.local/share/virtualenvs/blog-simple-neural-network-F0Tscko_/lib/python3.11/site-packages (from torch) (4.12.2)
Collecting sympy
Downloading https://download.pytorch.org/whl/sympy-1.12-py3-none-any.whl (5.7 MB)
[2K [38;2;114;156;31m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━[0m [32m5.7/5.7 MB[0m [31m57.2 MB/s[0m eta [36m0:00:00[0m MB/s[0m eta [36m0:00:01[0m
[?25hCollecting networkx
Downloading https://download.pytorch.org/whl/networkx-3.2.1-py3-none-any.whl (1.6 MB)
[2K [38;2;114;156;31m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━[0m [32m1.6/1.6 MB[0m [31m58.6 MB/s[0m eta [36m0:00:00[0m
[?25hRequirement already satisfied: jinja2 in /home/seba/.local/share/virtualenvs/blog-simple-neural-network-F0Tscko_/lib/python3.11/site-packages (from torch) (3.1.4)
Collecting fsspec
Downloading https://download.pytorch.org/whl/fsspec-2024.2.0-py3-none-any.whl (170 kB)
[2K [38;2;114;156;31m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━[0m [32m170.9/170.9 kB[0m [31m18.5 MB/s[0m eta [36m0:00:00[0m
[?25hRequirement already satisfied: MarkupSafe>=2.0 in /home/seba/.local/share/virtualenvs/blog-simple-neural-network-F0Tscko_/lib/python3.11/site-packages (from jinja2->torch) (2.1.5)
Collecting mpmath>=0.19
Downloading https://download.pytorch.org/whl/mpmath-1.3.0-py3-none-any.whl (536 kB)
[2K [38;2;114;156;31m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━[0m [32m536.2/536.2 kB[0m [31m42.9 MB/s[0m eta [36m0:00:00[0m
[?25hInstalling collected packages: mpmath, sympy, networkx, fsspec, filelock, torch
Successfully installed filelock-3.13.1 fsspec-2024.2.0 mpmath-1.3.0 networkx-3.2.1 sympy-1.12 torch-2.3.1+cpu
Matplotlib, pour faire de jolis graphiques.
!pip install matplotlib
from matplotlib import pyplot as plt
%matplotlib inline
Collecting matplotlib
Downloading matplotlib-3.9.0-cp311-cp311-manylinux_2_17_x86_64.manylinux2014_x86_64.whl (8.3 MB)
[2K [38;2;114;156;31m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━[0m [32m8.3/8.3 MB[0m [31m44.0 MB/s[0m eta [36m0:00:00[0mm eta [36m0:00:01[0m0:01[0m:01[0m
[?25hCollecting contourpy>=1.0.1
Using cached contourpy-1.2.1-cp311-cp311-manylinux_2_17_x86_64.manylinux2014_x86_64.whl (306 kB)
Collecting cycler>=0.10
Using cached cycler-0.12.1-py3-none-any.whl (8.3 kB)
Collecting fonttools>=4.22.0
Downloading fonttools-4.53.0-cp311-cp311-manylinux_2_17_x86_64.manylinux2014_x86_64.whl (4.9 MB)
[2K [38;2;114;156;31m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━[0m [32m4.9/4.9 MB[0m [31m57.3 MB/s[0m eta [36m0:00:00[0m31m72.7 MB/s[0m eta [36m0:00:01[0m
[?25hCollecting kiwisolver>=1.3.1
Using cached kiwisolver-1.4.5-cp311-cp311-manylinux_2_17_x86_64.manylinux2014_x86_64.whl (1.4 MB)
Requirement already satisfied: numpy>=1.23 in /home/seba/.local/share/virtualenvs/blog-simple-neural-network-F0Tscko_/lib/python3.11/site-packages (from matplotlib) (1.26.4)
Requirement already satisfied: packaging>=20.0 in /home/seba/.local/share/virtualenvs/blog-simple-neural-network-F0Tscko_/lib/python3.11/site-packages (from matplotlib) (24.1)
Collecting pillow>=8
Using cached pillow-10.3.0-cp311-cp311-manylinux_2_28_x86_64.whl (4.5 MB)
Collecting pyparsing>=2.3.1
Using cached pyparsing-3.1.2-py3-none-any.whl (103 kB)
Requirement already satisfied: python-dateutil>=2.7 in /home/seba/.local/share/virtualenvs/blog-simple-neural-network-F0Tscko_/lib/python3.11/site-packages (from matplotlib) (2.9.0.post0)
Requirement already satisfied: six>=1.5 in /home/seba/.local/share/virtualenvs/blog-simple-neural-network-F0Tscko_/lib/python3.11/site-packages (from python-dateutil>=2.7->matplotlib) (1.16.0)
Installing collected packages: pyparsing, pillow, kiwisolver, fonttools, cycler, contourpy, matplotlib
Successfully installed contourpy-1.2.1 cycler-0.12.1 fonttools-4.53.0 kiwisolver-1.4.5 matplotlib-3.9.0 pillow-10.3.0 pyparsing-3.1.2
from random import randint, seed
Création d’un jeu de données simple
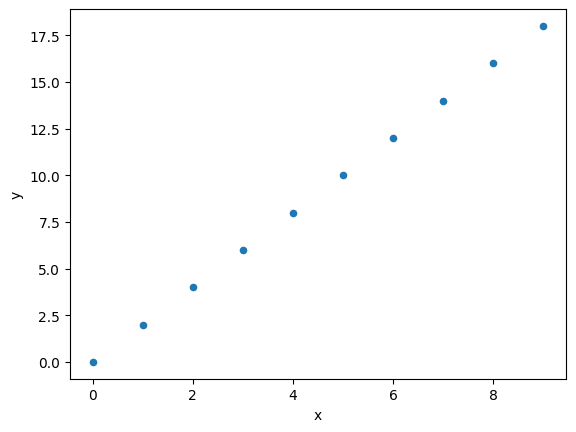
Pour le principe de la démonstration, on va créer un jeu de données parfaitement linéaire f(x) = 2*x
On pourra contrôler facilement que les prévisions du réseau sont bien sur cette droite.
data = pd.DataFrame(columns=["x", "y"],
data=[(x, x*2) for x in range(10)],
)
data["x"] = data["x"].astype(float)
data["y"] = data["y"].astype(float)
data.plot.scatter(x="x", y="y")
<Axes: xlabel='x', ylabel='y'>
data
Démarrage
Préparons quelques variables pour le projet. Nous initions aussi le modèle M, si vous voulez tester des évolutions dans le code, relancez cette cellule pour réinitialiser le modèle.
# On fait en sorte que pytorch tire toujours la même suite de nombres aléatoires
# Comme ça vous devriez avoir les mêmes résultats que moi.
torch.manual_seed(1337)
seed(1337)
# Je crée mon réseau d’un neurone avec une valeur aléatoire
M = torch.randn((1,1))
# On active le calcul du gradient dans le réseau
M.requires_grad = True
print(M)
# On garde une liste de pertes pour plus tard
losses = list()
tensor([[-2.0260]], requires_grad=True)
Algorithme général
Pour que notre réseau apprenne des données, il nous faut une phase de feed forward et une back propagation.
En quoi ça consiste ?
Prenons un exemple dans notre jeu de données, la ligne x=9 et y=18.
# on prend un échantillon
ix = randint(0, len(data)-1) # Indice de X
x = data.iloc[ix]["x"]
y = data.iloc[ix]["y"]
print(f"{x=},{y=}")
x=9.0,y=18.0
La phase de feed forward consiste à demander au modèle ce qu’il prévoit comme donnée pour x=9. On utilise l’opérateur “@” qui multiplie des tenseurs.
X = torch.tensor([x])
y_prevision = M @ X
---------------------------------------------------------------------------
RuntimeError Traceback (most recent call last)
Cell In[10], line 2
1 X = torch.tensor([x])
----> 2 y_prevision = M @ X
RuntimeError: expected scalar type Float but found Double
Ah oui, Numpy convertit notre Float (32bits) en Double (64 bits) en interne. Transformons notre tenseur en Float dans ce cas.
X = torch.tensor([x]).float()
y_prevision = M @ X
print(f"{y_prevision=}")
y_prevision=tensor([-18.2339], grad_fn=<MvBackward0>)
Notre modèle prédit donc “-18.2339”, alors que notre y vaut 18.
C’est normal puisque l’on a initialisé notre modèle avec des valeurs complètement aléatoires.
Il nous faut donc corriger notre modèle, mais d’abord nous allons utiliser une fonction de perte, ici l1_loss pour voir à quel point on se trompe.
Y = torch.Tensor([y])
loss = F.l1_loss(y_prevision, Y)
print("loss", loss.item())
loss 36.23392868041992
On se trompe de 36 (c’est à dire 18 – 18,23), c’est beaucoup.
Pour corriger le modèle nous allons faire la phase de back propagation (ou rétro-propagation ou backward pass).
Nous allons demander à Pytorch de calculer l’impact des poids du modèle dans cette décision. C’est le calcul du gradient. Cette opération, sans être très compliqué car il s’agit de dériver toutes les opérations effectuées, mérite un article à part entière et ne sera pas traitée dans celui-ci.
# backward pass
M.grad = None
loss.backward()
Attention, il faut toujours réinitialiser le gradient avant de lancer le back propagation.
Maintenant que nous avons un gradient, nous allons mettre à jour notre modèle en y appliquant une fraction de ce tenseur.
Pourquoi qu’une fraction ? Ici nous avons une fonction linéaire très simple à modéliser. En appliquant le gradient, on corrigerait tout de suite le modèle. Le problème est que, dans la vraie vie, la situation n’est jamais aussi simple. En réalité, les données sont hétérogènes et donc, appliquer le gradient à une donnée améliore le résultat pour celle-ci mais donnerait un très mauvais gradient pour les autres données.
Nous allons donc appliquer une fraction du gradient et essayer de trouver le meilleur compromis. On pourra déterminer celui-ci grâce à la fonction de perte.
Nous allons donc appliquer une modification de 0,1 fois le gradient sur notre modèle, ce 0.1 s’appelle le learning rate.
# update
lr = 0.1
M.data += -lr * M.grad
print(f"{M.grad=}, {M.data=}")
M.grad=tensor([[-9.]]), M.data=tensor([[-1.1260]])
Nous verrons lors d’un autre article comment choisir le learning rate.
Voyons ce que ça donne :
# forward pass
y_prevision = M @ X
print(f"{y_prevision=}")
y_prevision=tensor([-10.1339], grad_fn=<MvBackward0>)
Pas si mal, on passe de -18 à -10. Ça reste très mauvais mais on n’a exécuté qu’une seule fois notre cycle feed forward / back propagation.
Faisons en sorte d’appeler plusieurs fois notre algorithme.
for i in range(1000):
# on prend un échantillon
ix = randint(0, len(data)-1)
x = data.iloc[ix]["x"]
y = data.iloc[ix]["y"]
# forward pass
y_prevision = M @ torch.tensor([x]).float()
loss = F.l1_loss(y_prevision, torch.Tensor([y]))
# backward pass
M.grad = None
loss.backward()
# update
lr = 0.01
M.data += -lr * M.grad
# stats
losses.append(loss.item())
Voyons ce que donne notre prévision dans un graphique. En rouge les points de données, en bleu la courbe de prévision.
ax = data.plot.scatter(x="x", y="y", color="red")
prevision = pd.DataFrame(np.arange(10), columns=["x"])
m = M.detach()
prevision["y_prevision"] = prevision["x"].apply(lambda x: (m @ torch.tensor([float(x)]))[0].numpy()) #torch.tensor([4.])
prevision.plot(y="y_prevision", ax=ax, x="x")
<Axes: xlabel='x', ylabel='y'>
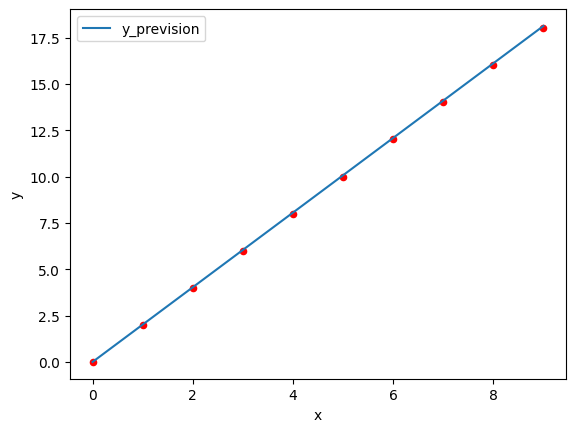
Et si nous sortons du cadre des données avec un X de 2000 ?
m @ torch.tensor([float(2000)])
tensor([4028.0156])
Pas mal, on devrait avoir 4000 mais c’est déjà mieux.
Et par rapport à nos données de base ?
prevision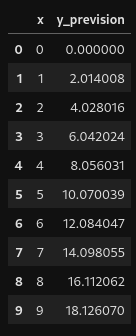
Bon, que ce passe-t-il ? Regardons un peu l’évolution de notre perte en fonction des itérations ?
pd.DataFrame(losses, columns=["loss"]).plot()
<Axes: >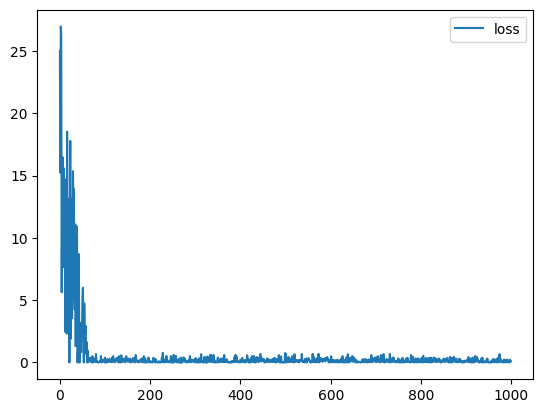
On voit que les pertes sont importantes pendant 100 itérations et ensuite elles se stabilisent un peu entre 0 et 0.8.
Est-ce qu’on peut améliorer ça ? Oui très facilement, nous verrons cela ensemble lors d’un prochain article.
Conclusion
Nous avons appris comment créer un modèle et faire un apprentissage avec les phases de feed forward et back propagation. Ensuite nous avons vu que le learning rate et gradient permettent de corriger le modèle petit à petit. En faisant quelques centaines d’itérations nous avons un bon modèle de régression.
J’espère que cette petite introduction vous a donné envie d’aller plus loin.
Rédacteur : Sébastien Da Rocha